
Are You Paying Attention to Attention Is All You Need?
The 2017 paper that 8 Google researchers published — then immediately quit to build companies from — quietly became the blueprint for every AI tool you use today. Here's what it actually means for your business.


If you're not paying attention to how it works, you're flying blind in the most important technology shift of your generation.
There's a paper published in 2017 that most business leaders have never read, probably never heard of, and almost certainly should care about. It's called Attention Is All You Need. It was written by eight researchers at Google — and almost immediately after publishing it, every single one of them left to found or join other companies. Make of that what you will.
The paper introduced something called the Transformer architecture. Today, it's the foundational structure underneath ChatGPT, Claude, Gemini, Llama, DeepSeek, and essentially every large language model that has changed how your team works, how your customers are served, and how your competitors are moving.
It's been cited over 173,000 times, placing it among the most-cited research papers of the entire 21st century. If the internet was built on TCP/IP, modern AI was built on this paper.
So what does it actually say?
And why should you care beyond knowing it exists?
The Problem It Was Solving (Told Without the Math)
Before 2017, AI systems that worked with language — translation, summarization, question answering — relied on a structure called Recurrent Neural Networks, or RNNs. The way an RNN processed text was almost charmingly sequential: it read a sentence word by word, left to right, like a person sounding out words on a page. The problem was that by the time it got to the end of a long sentence, it had basically forgotten the beginning. The technical term is the "vanishing gradient problem." The human term is: it didn't really understand context.
Imagine asking an intern to summarize a 200-page contract by having them read it one word at a time and not being allowed to flip back. You'd get... something. But probably not a reliable output.
The Transformer architecture changed the game by doing something elegant. Instead of reading sequentially, it asks — at every step — "what else in this text should I be paying attention to right now?" It's called the attention mechanism, and it works by comparing every word to every other word simultaneously. Not one after another. All at once.
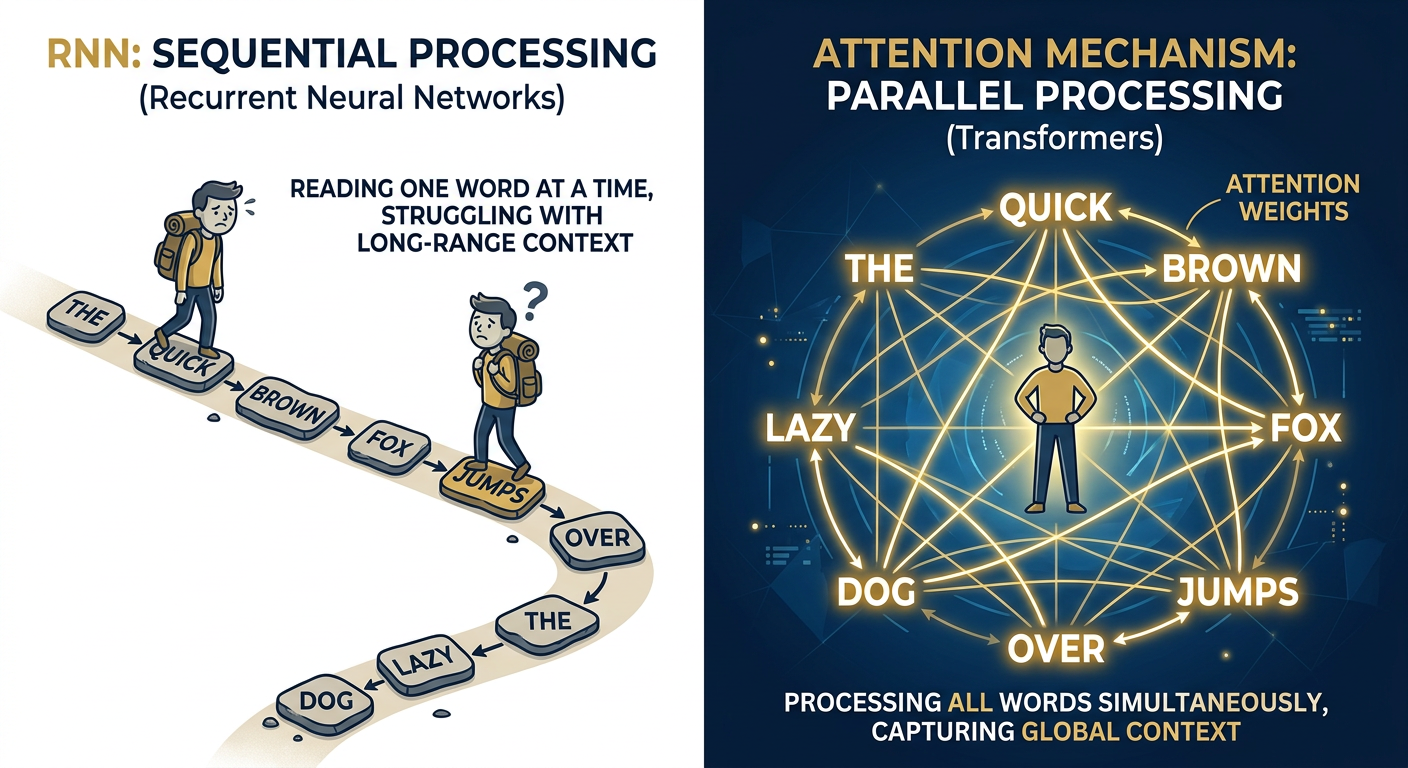
The result is that the model actually understands context. It knows that "bank" in a sentence about rivers means something different than "bank" in a sentence about interest rates. It understands that the pronoun "it" in a paragraph refers to a specific noun three sentences earlier. It can reason about long documents, hold multi-step instructions, and generate coherent, contextually grounded output. That's the engine under every AI product you're currently evaluating, buying, or building on.
The title, by the way, is a riff on the Beatles song All You Need Is Love. The authors named their internal team "Team Transformer" partly because one of them just liked the sound of the word. The original design document apparently included cartoon characters from the Transformers franchise. Sometimes the most consequential things start with a bit of personality.
Why This Matters Right Now — Especially If You're Not a Big Enterprise
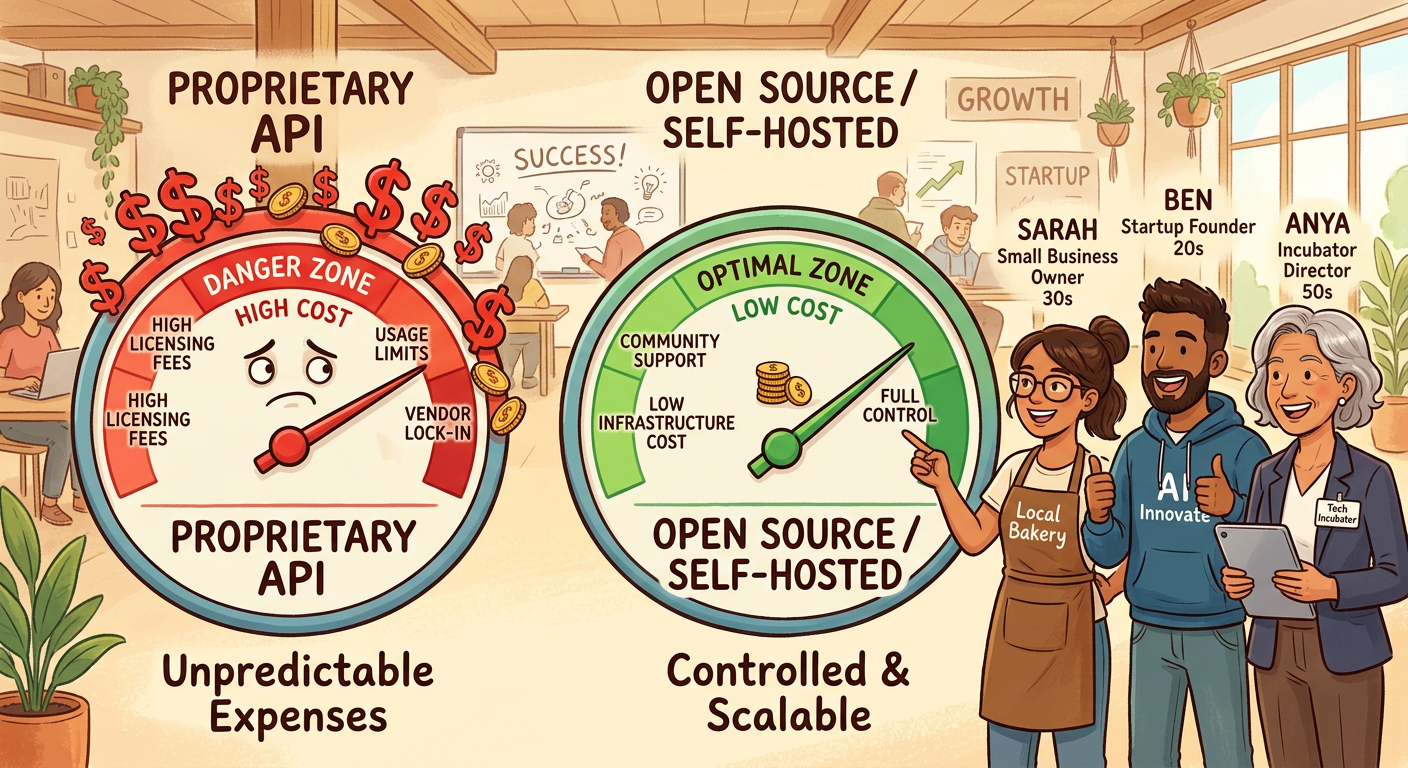
Here's where it gets practical. The Transformer architecture made AI models extraordinarily capable, but it also made them extraordinarily hungry — for compute, for memory, for electricity, for money. Training GPT-4 reportedly cost well over $100 million. Running these models at scale, through API calls, costs anywhere from $10 to $70 per million tokens with the major proprietary providers.
For a Fortune 500 company, that's a line item. For a startup, a growth-stage SMB, or a founder running experiments across three product ideas simultaneously, it's a ceiling. It's the thing that stops you from building. It's the invisible gate that says "AI is for the big players."
That narrative is breaking apart in real time.
The open source AI ecosystem — driven by Meta's Llama family, DeepSeek's reasoning-focused models, Mistral's efficient architectures, and Alibaba's Qwen — has changed the cost equation dramatically. The same Transformer architecture, the same attention mechanisms, the same foundational ideas from that 2017 paper — now available as open weights that organizations can run themselves. The 2026 Open Source AI Landscape research is clear: open models now deliver roughly 85% of the capability of top proprietary systems, at a fraction of the cost. We're talking sub-dollar per million tokens via third-party hosting, and cents-on-the-dollar for self-hosted deployments.
Enterprise GenAI spend hit $37 billion in 2025, growing at 3.2x year-over-year. That number doesn't represent a market that's slowing down to wait for you. It represents a market that's accelerating and creating competitive distance between organizations moving now and those still waiting for a clearer picture.
For incubators and accelerators, this is directly relevant to what you're advising your cohorts on. The infrastructure cost assumptions that made AI feel out of reach twelve months ago are being restructured by open ecosystems. Startups that correctly time this shift — that build on open foundations, avoid proprietary lock-in, and deploy on hybrid or on-prem infrastructure — will have structural cost advantages that compound over time.
For the growth-oriented SMB or the change-oriented leader inside a mid-market company: this is the moment where you stop watching and start building. The Transformer is the engine. Open source made it accessible. The question now is operational: who's helping you run it?
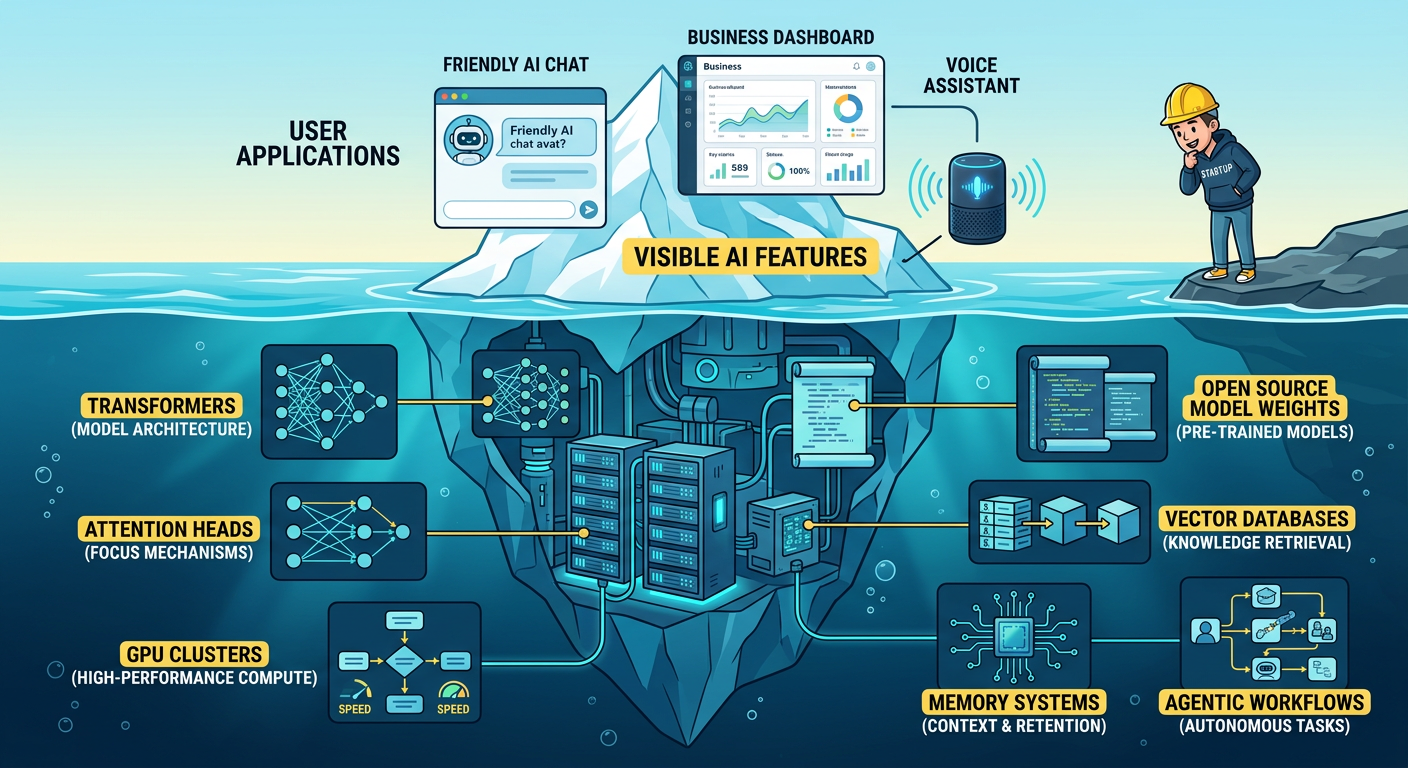
The Infrastructure Problem Nobody Talks About Enough
Understanding the Transformer is one thing. Deploying it profitably at scale is another conversation entirely.
The attention mechanism — brilliant as it is — is computationally expensive by nature. Asking a model to compare every token against every other token in a large document means the compute requirements scale quadratically with context length. In plain language: longer prompts, longer documents, more complex agentic workflows — they all get expensive fast. This is the dirty secret behind a lot of AI demos that look incredible in pitch decks but become budget nightmares in production.
There's a reason the open source community has become obsessed with inference optimization. Tools like vLLM — which became GitHub's top open source project by contributors in 2025, surpassing even Kubernetes — exist specifically to make Transformer-based inference faster and cheaper. Quantization, speculative decoding, efficient attention kernels: these aren't academic curiosities. They're the difference between a product that's economically viable and one that bleeds cash.
This is exactly the problem Cetacean Labs is going after with the Oceanic platform. Rather than treating AI infrastructure as a procurement decision — buy an API, hope it works, pay whatever the vendor charges — Oceanic is built on the premise that organizations should own their AI stack the way they own their data. The platform enables agent orchestration, real-time intelligence, and persistent memory across hybrid cloud and on-premises deployments, using open-weight models that can be fine-tuned and customized without sending your data to someone else's servers.
The practical upside: teams building on Oceanic can deploy production-grade agentic workflows — the kind of systems where AI doesn't just answer questions but plans, retrieves information, executes multi-step tasks, and learns from outcomes — without paying proprietary API rates every time a token gets processed. For a startup running thousands of agentic operations per day, or an SMB building a customized AI application for their specific industry, the economics matter enormously.
Cetacean also sits at an interesting intersection: they're not just an infrastructure company. Through their work with IEEE, enterprise deployments at scale, and the Esteemed Colleagues talent network, they're actively building the practitioner layer — the human expertise that makes AI infrastructure actually work in production. Because there's one thing the 2017 paper didn't solve, and that open source hasn't solved either: the talent and implementation gap. The models are available. Running them well, at cost, safely, and in alignment with your business goals is still genuinely hard. That gap is where real value gets created right now.
What Business Leaders Should Actually Take Away
You don't need to understand scaled dot-product attention to make good AI decisions for your business. What you do need to understand is this:
Every capable AI system you use today — the chatbots, the code assistants, the document summarizers, the customer service agents, the research tools — runs on the architecture described in that 2017 paper. The Transformer is not one approach among many. It won. It is the architecture. The question is no longer whether to use Transformer-based AI. It's whether you'll use it in a way that gives you ownership, cost control, and competitive advantage, or whether you'll rent access to someone else's version of it indefinitely.
The open source movement has democratized the model layer. What's getting clearer in 2026 is that the real competitive differentiation isn't which model you use — it's how well you deploy it, how much you can customize it with your own data, and how efficiently your infrastructure runs it.
For startup founders: your cost structure around AI will determine your margins and your ability to iterate. Build on open foundations wherever possible. Don't let proprietary API costs become a ceiling on your experimentation.
For incubators and accelerators: the cohorts you're running right now are making foundational infrastructure decisions that will define their unit economics for years. The open source AI landscape is mature enough to advise on. Get current on it.
For growth-oriented SMBs and business leaders pushing change: the Transformer architecture gave every organization in the world access to a fundamentally new kind of intelligence. The 2026 open source ecosystem made it affordable. The infrastructure layer is catching up. The window for building meaningful AI capability before your competitors figure this out is not infinite.
Pay attention. That's kind of the whole point.
A WORD FROM OUR ARTICLE SPONSOR
Cetacean Labs builds AI infrastructure for the autonomous economy through the Oceanic platform — supporting agent orchestration, real-time intelligence, and hybrid/on-prem deployment for organizations that want to own their AI stack.
Explore the AI Platform at oceanicai.io
And, you see the latest insight on AI Tech at the Open Source AI Landscape Report.
Open Source Report [https://cetacean-oss.b2bcontentartist.com]




